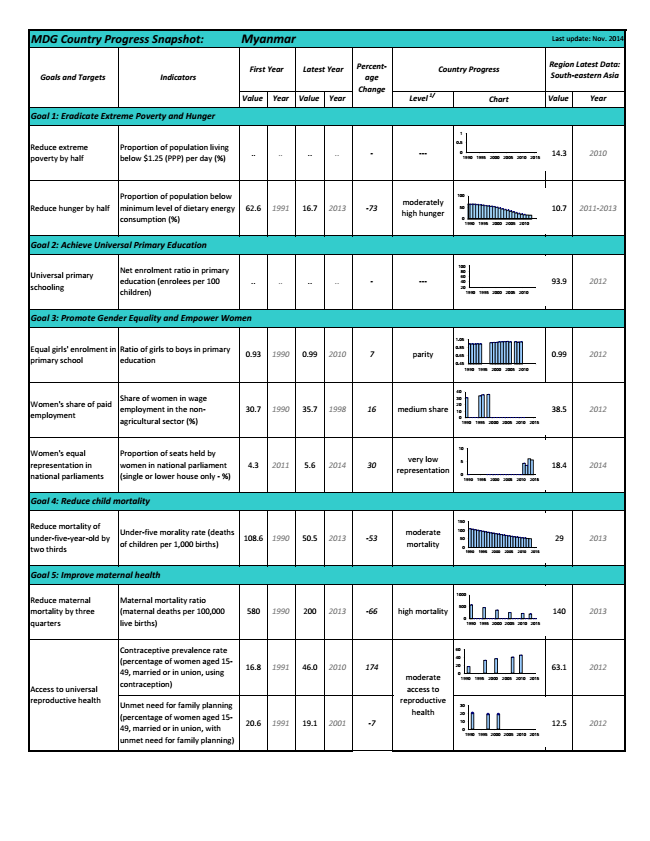
It wouldn't matter if it's the right or the left one that is
usable he would find from a pair of broken slippers. That was in the seventies
that a farmer in a village in the Shwebo Township, who happened to be the elder
brother of one Dr. Ba Kyi of Mandalay University, told me of a history student
who went around village to village doing research. When this student found a
single good slipper from a broken pair he would put it in his shoulder bag for
later use. Last week when I told this story to my retired friend in Mandalay,
himself a graduate from the Mandalay University, this friend told me that Dr.
Ba Kyi was a professor of math and that I must have met his brother in Chi-pa,
a large village near Shwebo town. By the way, I don't remember if I had asked
the name of the history student who saved broken slippers and forgot his name
or if the farmer didn't know his name or if I hadn't asked at all.
A lot of people think Wikipedia is the flipside of Encyclopedia
Britannica and "flipside" would mean inferior, if you like. For me Wiki is just another encyclopedia and
it is just about the only encyclopedia I used for a long time. Before that I
used to have a pirated copy of Encarta and it was fine. From the time both
Google and Wiki existed, I looked in Wiki, then go to the links given there and
then also looked in Google for more. This habit stuck because Internet makes it
so easy for us to find information. In my experience for example, when I played
around with "R" the free statistical software I found its output of
results in scientific notation in some calculations really annoying. Well, I
didn't try looking for the solution to get plain number output from R's 3400+ page
reference manual. I looked for it on the Web and got instant gratification. As
for the Wiki vs. Britannica issue, it never occurred to me that what's in Wiki
would be weak and then to check that out with Brit when Brit becomes online. And
I haven't even really tried its free online version with pop-ups and
advertising.
This wandering of thoughts started when I chanced to watch a
seminar organized by the Sarpay-beikman
library with highly respected retired librarian of Rangoon University Library,
U Thaw Kaung moderating, with two lady librarians as panelists. I happened to
tuned-in that TV broadcast right in the middle and had seen only a part of it,
but I could appreciate the efforts made by our librarians to move towards
open-shelf access to the library, helping visitors, and in embracing new technologies
like scanners, computers and the Internet. Then there was one practical advice
by the moderator—not to cite Wikipedia as reference as it is not as reliable as
for example, Encyclopedia Britannica.

Well, I was vaguely aware that there has been (and still is)
such advice on the Web and elsewhere, yet I thought I have nothing to do with
that because all I need is to look for some introduction to what I am
interested at some moment and for that Wiki suits me well, and to be frank I
don't want my cellular data connection ticking away too long and Wiki is
something of a great one-stop shopping. However, now that I heard this advice
from a venerable librarian, I take that's great advice at least for researchers
and the academia.
It is understandably so, because, Britannica "is written by about 100 full-time editors and more than
4,000 contributors, including 110 Nobel Prize winners
and five American
presidents" (Encyclopædia
Britannica, Wikipedia). All the same, I felt that for ordinary folks and guys
like us, using Wiki would somehow be like collecting a single good slipper for
future use. Unsavory may be, but not illogical.
Yet that is not the end of story because curiosity nagged me
to look a bit further. Perhaps there somewhere under the skies was someone who
perfectly fit the single slipper, not a Cinderella, but plain, strong, working
class lass for our student. According to Wikipedia "The 2013
edition of Britannica contained approximately forty thousand
articles, and by comparison to Wikipedia, was over one hundred times smaller
than the current number of articles contained in Wikipedia - specifically, 4,714,319 articles in English (as of February 8, 2015)."
On the other hand, Wikipedia allows any user to create and
edit its articles. It seems obvious from that a bunch of nobodies however large
in numbers would be no match for a band (4,000 strong!) of polished scholars,
professionals and luminaries. However, that's a great topic to fight about and
not only there has been heated debate about Brit vs. Wiki in specifics, but
also battles on the wider fronts of crowd vs. experts, and the merits of open
collaboration vs. traditional hierarchical structures.
Anyway, it may be particularly distasteful for the academia
when someone says the taboo on Wikipedia is a problem of culture than other
things (Students Should Be Allowed To
Cite Wikipedia, Ellen Fishbein, The Observer, May 1, 2014):
You’re writing a paper, you Google your topic,
and the search returns that first, magical article: the Wiki page. Perfectly
free of tedious language, abstractions or scholarly euphemisms, it gives you
what you need. You go to Encyclopedia Britannica; you look up the article on
your topic. You see a few dry, grammatically correct lines interspersed with
the same facts you saw on Wiki. “Good enough,” you think, and you footnote it.
Maybe you get fancy: Instead of looking for
another encyclopedic source, you scroll down to Wikipedia’s list of citations.
You open the pages, skim them for relevance and add them to your bibliography.
...
But the ban on Wikipedia in
academic circles is not a problem of denial—it’s a problem of culture.
But the big scholars stay aloof while the masses and even
people like the Supreme Court Judges of India (Indian high courts show continued enthusiasm for citing Wikipedia, Alok
Prasanna Kumar, Live Mint, 10 February 2015) trust Wikipedia:
Wikipedia use remains fairly widespread among the high
courts of India. No fewer than 18 out of 20 high courts in the last 10 years
(excluding the newly constituted high courts of Manipur, Meghalaya, and
Tripura) have referred to Wikipedia as an authority at least once in their
judgements.
A detailed search of legal databases reveals that no fewer
than 84 high court judgements that cite Wikipedia as an authority.
The question is why those big scholars didn't try improving
Wikipedia by writing articles and by editing. As Neil Selwyn, a professor in
the faculty of education at Monash University and the lead author of the
Wikipedia study, noted (Wikipedia not
destroying life as we know it, John Ross, THE AUSTRALIAN, February 11, 2015).
... if Education Minister Christopher Pyne wants Australians
universities to have real impact, the best way would be to force professors to
spend a week editing Wikipedia pages in their areas of expertise.
“In terms
of making a real contribution to public knowledge, what better thing could we
do?
“I go online and look at stuff in my area and it’s really
shocking. But I have not been on there to make it any better, because I’ve got
to write grant proposals and academic articles that no one will ever read.”
Ross summed up the findings of the
Monash University Study that "students and academics alike are missing a giant opportunity
to contribute to world knowledge by shunning the right to edit the world’s
sixth most used website."
There were much criticism and complaints about the editing
system of Wikipedia by outsiders as well as insiders and that may also be one
reason why the big scholars choose to stay aloof. According to Tom Simonite in The Decline of Wikipedia, MIT Technology
Review, October 22, 2013 (http://www.technologyreview.com/featuredstory/520446/the-decline-of-wikipedia/#comments):
In the established model,
advisory boards, editors, and contributors selected from society’s highest
intellectual echelons drew up a list of everything worth knowing, then created
the necessary entries. Wikipedia eschewed central planning and didn’t solicit
conventional expertise. In fact, its rules effectively discouraged experts from
contributing, given that their work, like anyone else’s, could be overwritten
within minutes.
One commentator who joined Wikipedia in late September 2013 as
an editor posted his frustrations:
Craig_Weiler Oct
23, 2013
... The ideologues are
organized into a well oiled machine and know just how to game the
bureaucracy. There is no hope of getting around them or getting
Wikipedia to recognize this as a problem because they are embedded with
friendly administrators working on their side. They use "consensus"
to gang up on other editors and push their point of view into the
articles. They control hundreds of articles this way. Going up
against them is massively inefficient and a complete waste of a normal human's
time. ...
But one commentator in particular persistently condemned the
nonprofit Wikipedia for stealing the show from traditional for profit encyclopedias,
and worse for robbing the knowledge producers:
aestu Oct
24, 2013
... You
try to make it sound like for-profit encyclopedia processors are the maligned
"1%" profiting at the expense of everyone else. In reality,
publishing has always been a low-margin business, and not only are the
encyclopedia firms struggling to get by, but so are the original researchers
that produce the knowledge that fill those volumes and whose efforts are repaid
through consultancies and other fees.
As they say, why buy the cow if the milk is
free? How is research to be funded by the Wikipedia model?
aestu Oct
24, 2013
... Wikipedia's relationship
with the world of intellectual discovery is parasitical. Academics and
professionals produce the knowledge on their own time and at the expense of
themselves or their institutions. Wikipedia collects and posts it so that any
idiot can Google it up for free, but does nothing to fund or otherwise encourage
the discovery of knowledge.
...
Wikipedia has been a locust
swarm for many knowledge experts, from historians to scientists to literary
experts, who rely on consulting fees to put money in the fridge and pay for
their training and education. Wikipedia deprives these people of their
livelihoods.
aestu Oct 24, 2013
There is no free lunch. If research is not funded, there is
no research. Wikipedia relies on research for its content.
Encyclopedia publishers are not volunteers, and the research
they put in their materials comes from institutions and individuals who are
professionals at what they do. The fees that encyclopedia firms pay out to
those whose content populates their volumes pays for their professional pursuit
of knowledge.
Obviously, it's cheaper to simply
take than to buy, and that is why Wikipedia has an advantage. Wikipedia doesn't
pay back to the system that creates the content it uses.
aestu Oct 24, 2013
@ray-rogers @aestu
... Just because the use of a public
library is free to you, the end user, doesn't mean that the library is free in
the absolute. Many libraries around the world are feeling the crunch because
Wikipedia accomplishes the same goal without taxes or fees, but doesn't fund
research in the way libraries buying books for their shelves does.
aestu Oct 25, 2013
Wikipedia can't do that because traditional encyclopedia
editors are paid, tenured professionals whose cost is recouped in sales of the
encyclopedias they edit.
You can't hire "actual
experts" and keep WP free. There is no free lunch. Or, to be more
accurate, you get what you pay for.
dsgarnett Nov
21, 2013
... And where it's weak appears to be the
result (more and more often now) of a lack of a business reason for it to be
strong.
Seems most out of 310 comments altogether ignored those, but
a handful of the commentators replied:
apostasyusa Oct
24, 2013
... If there are in fact
competitors to Wikipedia, and they are for profit entities that are failures at
competing with a nonprofit, then what does that say about how they are running
their business?
Maybe they are giving way too much of their revenue to fund research?! What sort of examples do you have that demonstrate for profit encyclopedia publishers funding research?
Maybe they are giving way too much of their revenue to fund research?! What sort of examples do you have that demonstrate for profit encyclopedia publishers funding research?
apostasyusa Oct
24, 2013
@aestu
Wikipedia isn't free. People, including myself, donate to it.
You make it sound as if all research ever conducted is funded by encyclopedias. Can you show us all examples of research funded by encyclopedia companies. You make it sound as if their contribution is sorely missed and research that would otherwise be conducted is not.
You also make it seem as if the knowledge that research funding compiles, should only be to the benefit of those who pay for it. In that case encyclopedia Britannica would only be allowed to publish the data the company helped to find through research donations. ...
Wikipedia isn't free. People, including myself, donate to it.
You make it sound as if all research ever conducted is funded by encyclopedias. Can you show us all examples of research funded by encyclopedia companies. You make it sound as if their contribution is sorely missed and research that would otherwise be conducted is not.
You also make it seem as if the knowledge that research funding compiles, should only be to the benefit of those who pay for it. In that case encyclopedia Britannica would only be allowed to publish the data the company helped to find through research donations. ...
ray-rogers Oct 24, 2013
@aestu In
fact I never said or meant that the availability and acquisition of knowledge
was "free". The abstract point I was trying make is that the
distribution and availability of knowledge is a public and human good.
But to your point, the actual
establishment of many public libraries was considered a useful charity;
Benjamin Franklin and Carnegie were major contributors giving more or less
freely for what they, and I, consider the public good. ...
apostasyusa Oct
25, 2013
... Wikipedia only exists
because of donations. The fact that usage if free is of no consequence. ...
Fortunately for Wikipedia, people think it is important enough to fund it
independently and that the organization as a whole is fairly inexpensive to
operate.
gnorn Oct 25, 2013
@aestu When
did encyclopedias ever "fund original research"? Not for
centuries.
mspacek Oct 26, 2013
@aestu Gosh. Could you please provide some references for exactly
how Wikipedia freeloads off of original research? Since when is anyone or
anything responsible for paying for references? By your logic,
scientific articles should pay something to every other article they reference,
because otherwise how could real original research be funded?
More to the point, how does
referencing a source without contributing to it take anything away from that
source? It does the opposite. Increasing the visibility of a valuable source is
itself a valuable service. You have Wikipedia to thank for that service, which
it provides for free.
mspacek Oct 26, 2013
@aestu Your
arguments boil down to a love of centralization and executive power, and a
hatred and distrust of distributed power.
gnorn Nov
21, 2013
@dsgarnett Believe it or not, a lot of
people are motivated by an altruistic drive to share knowledge.
What can we say? Some seems to have an inherent distrust of
all altruistic efforts and would quickly dismiss them as sham or condemn their
products as inferior and wasteful or even as parasitic. I guess that such
distrust may more likely be traceable to cultural
origins than reason, and therefore mostly ignorable.
You'll find lots and lots of arguments and verdicts for and against
the phenomenon that is Wikipedia. I don't know if any other source of knowledge
printed or on-line, contained extensive documentation like Wiki for the types of criticisms leveled at it ("Criticism
of Wikipedia"), quotations from
critics of Wikipedia ("Wikipedia: Criticisms"), the reliability of Wikipedia compared to
other encyclopedias and more specialized sources ("Reliability
of Wikipedia") and even "Wikipedia: List of hoaxes on Wikipedia".
Now, if you need guidance in a nutshell from some prestigious
academic institution on how to use Wikipedia, you may like to try this (cited
in Criticism of Wikipedia).
The Academic Integrity at MIT handbook for students at Massachusetts
Institute of Technology states: 'Wikipedia is Not a Reliable
Academic Source: The bibliography published at the end of the Wikipedia entry
may point you to potential sources. However, do not assume that these sources
are reliable – use the same criteria to judge them as you would any other
source. Do not consider the Wikipedia bibliography as a replacement for your
own research."
MIT is the second ranked university out of 500 in the Best
Global Universities ranking by the current U.
S. News and World Report. However, you would be wiser after reading The Order of Things: What college rankings
really tell us by Malcolm Gladwell in New Yorker, February 14, 2011 (http://www.newyorker.com/magazine/2011/02/14/the-order-of-things?currentPage=all).
It's another story, though.
.jpg)